Naive Bayes for Record and Text Data
Naive Bayes for Record Data in R
Link to Data Set
Link to Code
Naive Bayes for Game Statistics
Game statistics such as Average Goals, Assists and Games were analyzed using Naive Bayes to determine their relationship with Estimated Earnings.
First Players were divided into those who have made more than 20 million dollars and those who have made less.
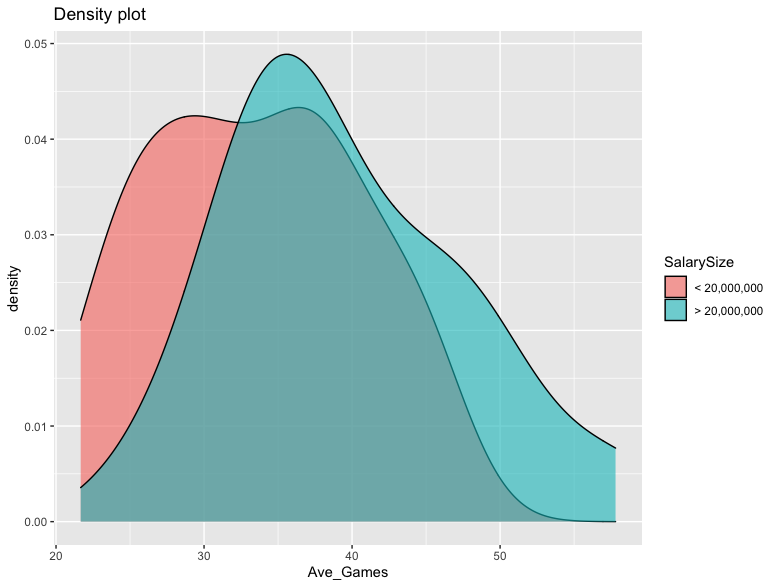
The exploratory visualizations are seen below.
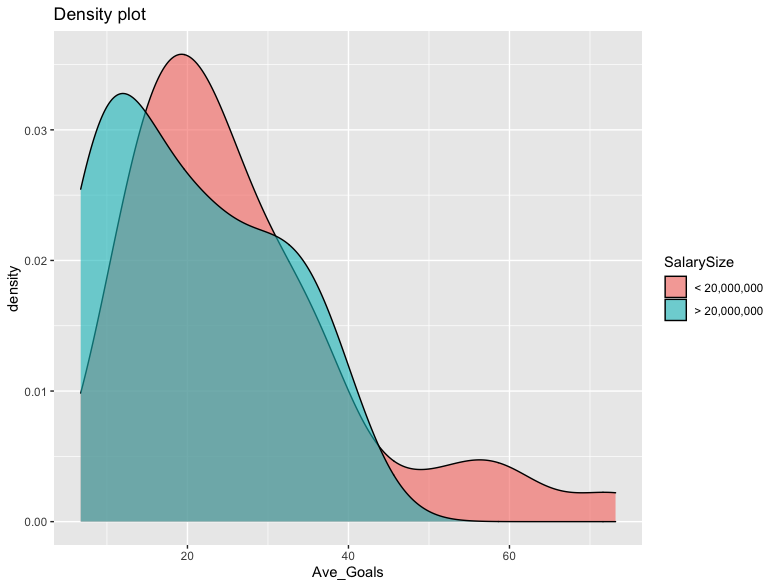
Density Plot of Average Goals for Greater or Less than 20 Million Earnings
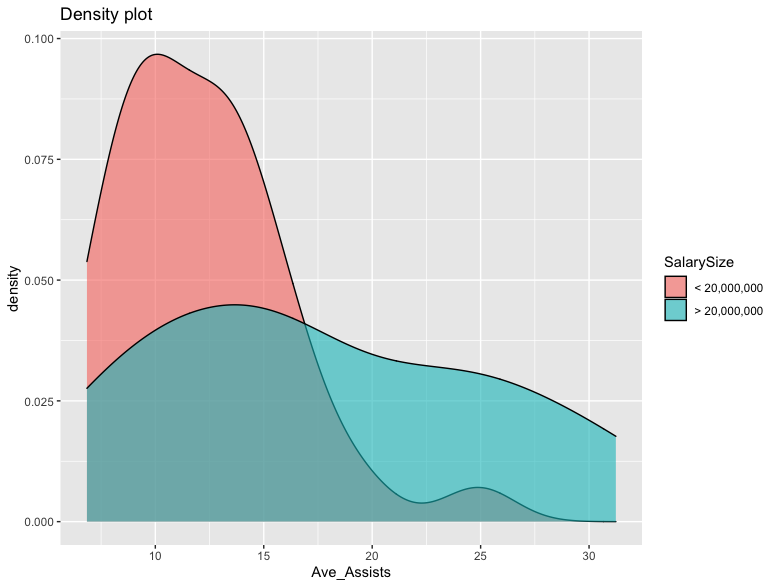
Density Plot of Average Assists for Greater or Less than 20 Million Earnings
Density Plot of Average Games for Greater or Less than 20 Million Earnings
The data was then analyzed using Naive Bayes Model. The model showed an accuracy of 91.7% with the confusion matrix shown below.
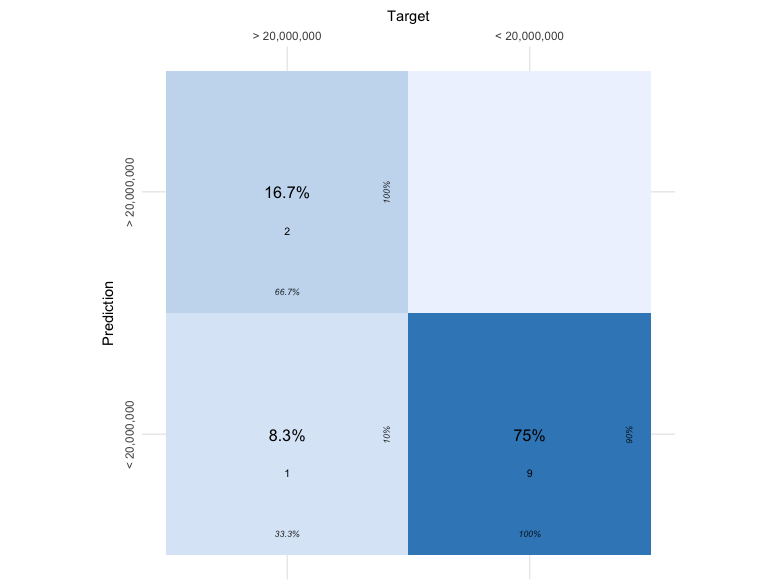
These results show that future salary groupings can be determined using game statistsics such as goals, assists and games.
More specifically the model can be used to predict if players are able to earn greater than 20 million dollars based off of their average game statistics.
This can be after further refinement could be potenitialiy used to help players negotiate the correct salary for their performance compared to current players.
Naive Bayes for Bio Statistics
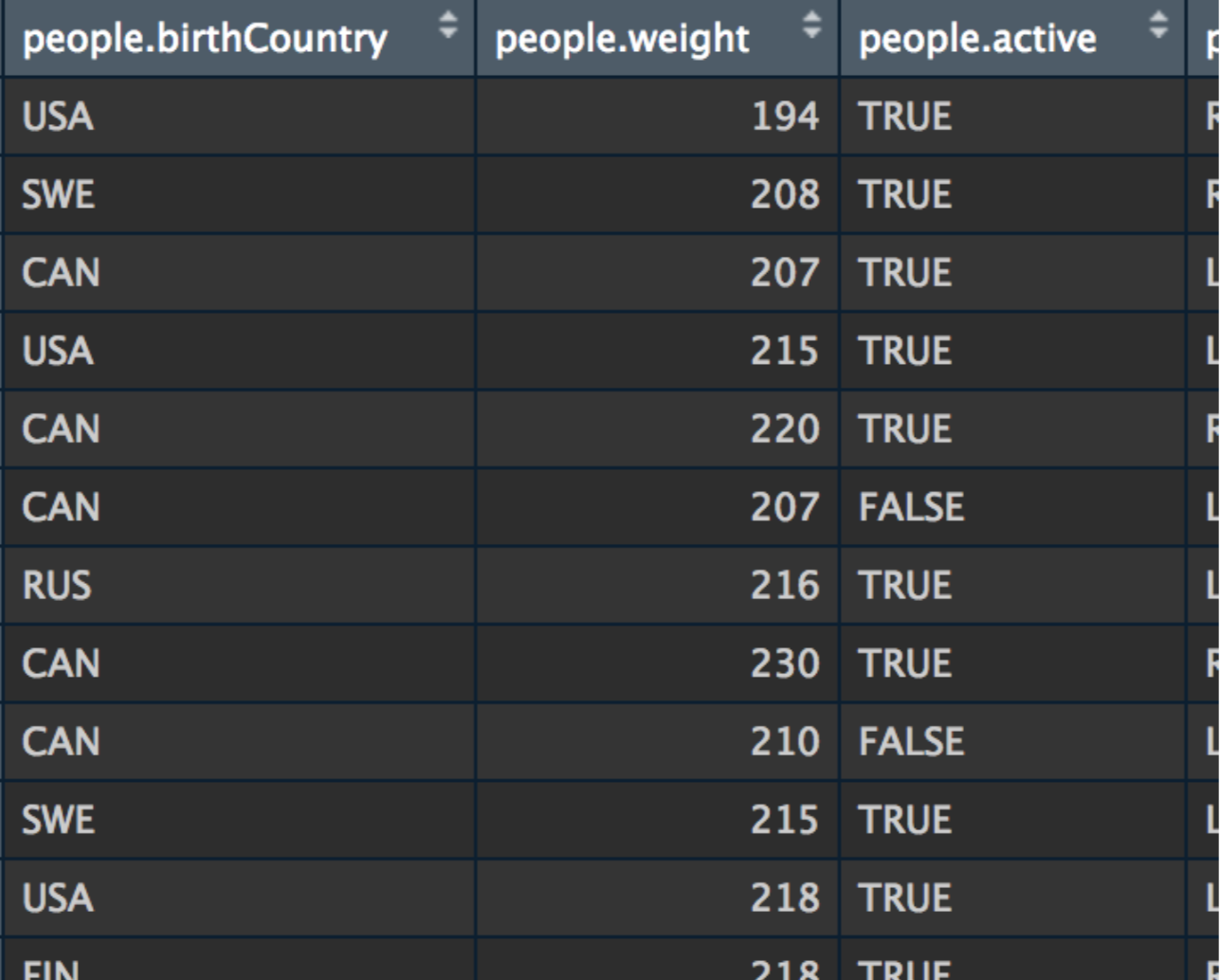
Biographical statistics such as Birth Month Relative to the Time of Year (Early, Middle, Late) and Birth Country were analyzed using Naive Bayes to determine their relationship with Estimated Earnings.
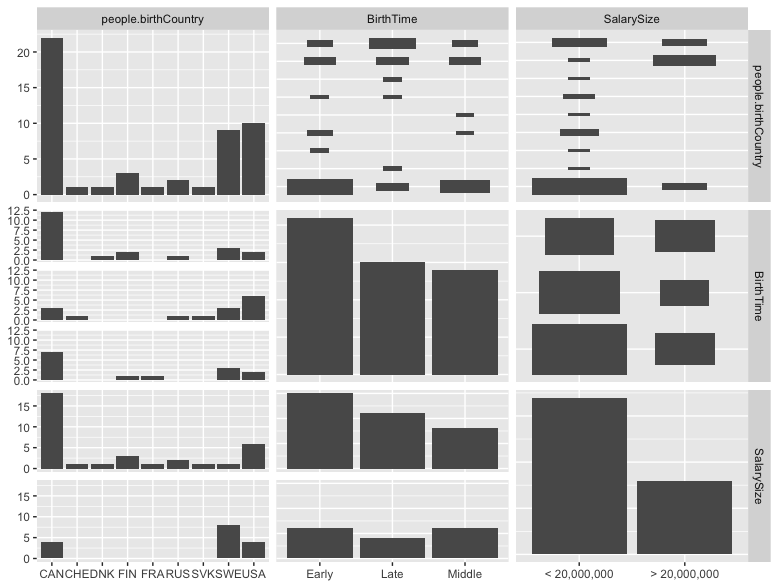
The Exploratory Visualizations are seen below.
Histogram Plots of Birth Month Time, Birth Country and Greater or Less than 20 Million Earnings
The Data was then analyzed using Naive Bayes Model. The model showed an accuracy of 75% with the confusion matrix shown below.
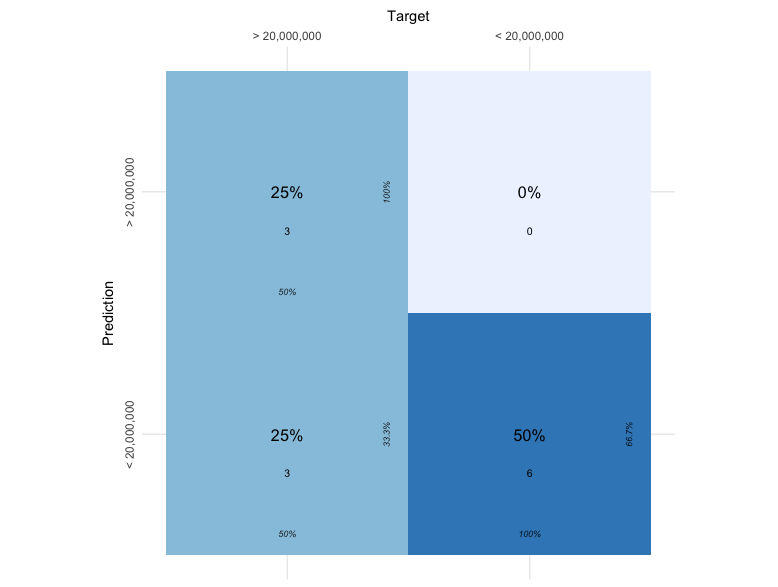
These results show that there is a relationship between Birth Countries and Birth Month Time with Estimated Earnings. This can give recruiters a better idea of the future potential of draftees based off of the birth country and time of year. This is because higher Earnings means the player is more skilled. Thus if players from certain countries or those born during a certain time of year are predicted to earn more, then they have a higher chance of being better. One explanation of this is level of competition and amount of time playing. Those who are born in certain countries might have stronger competition allowing them to become better as they grow up and those born durong a certain time might be placed into a certain age bracket that allows them to thrive and thus become better at the sport. Using this model, recruiters could use it as a tie breaker when deciding who to draft to choose the palyer with the best chance of being successful.
Naive Bayes for Text Data in Python
Link to Data Set
Link to Code
Naive Bayes for Twitter Data
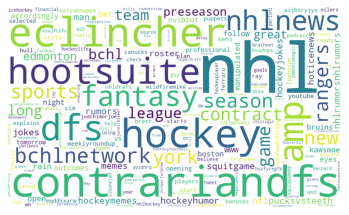
Tweets were collected centered around the hashtags NHLNews and NHL. They then were analyzed using Naive Bayes. The exploratory visualization of the text data is shown below.
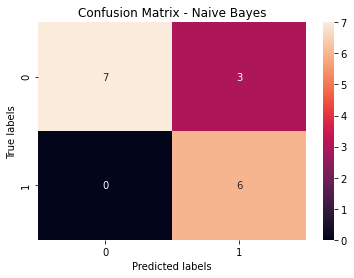
The data was analyzed using Naive Bayes with an accuracy of 81% as seen below in the Confusion Matrix.
The data was analyzed again suing a different groupings withteh Naive Bayes Model achieving an accuracy of 69% seen below.
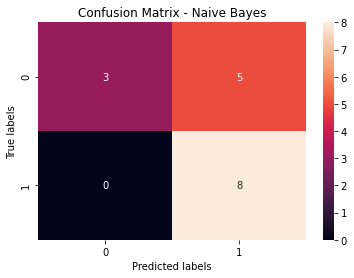
The model is able to differentiate the NHLNews tweets and the tweets just about the NHL. Using this model, tweets using other nhl associated hashtags can be analyzed and grouped into these categories. After these groupings occur, the tweets associated with NHLNews can be filtered to determine current trends in the player market and overall team statuses. This will help players decide where to play based off of public opinion on these changes the current teams. This will help teams make future decisions such as signing a certain player, the thoughts on team policies, fan feedback on new designs or logos, or what should be changed to make the hockey experience more enjoyable for fans.