Link to Raw Data

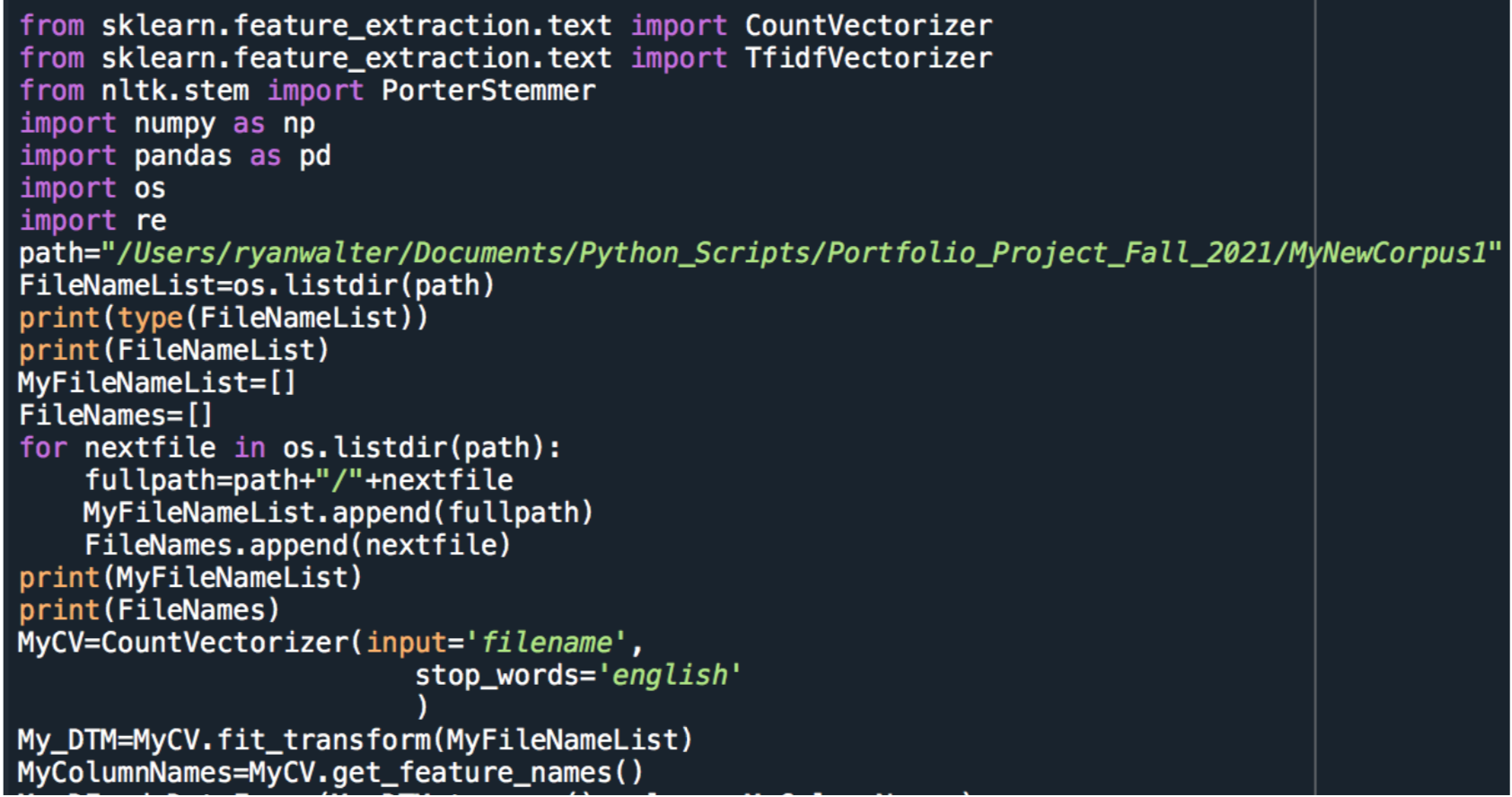
Link to Code
Link to Clean Data
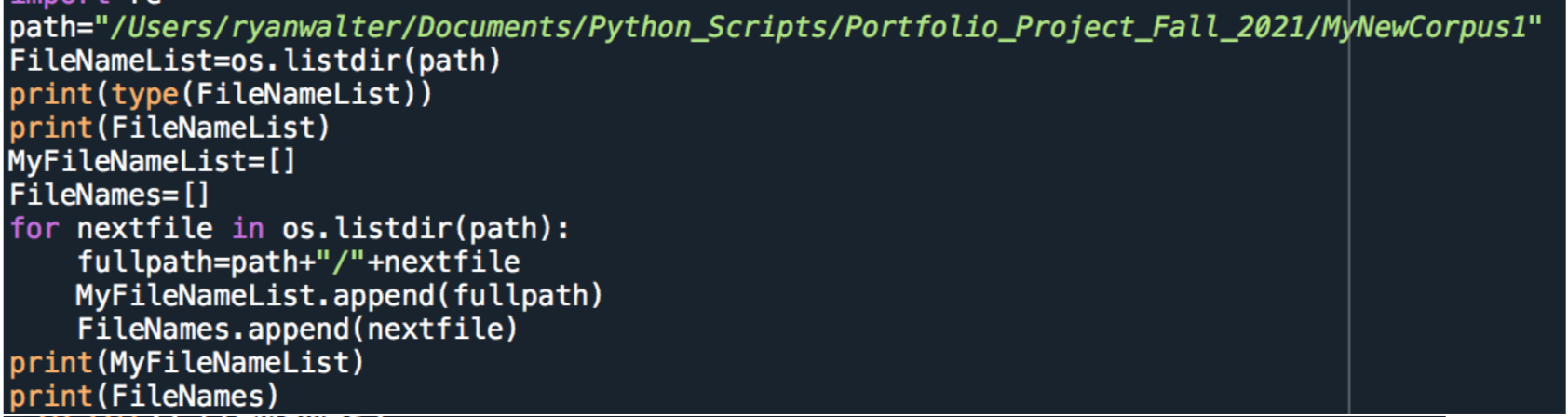
The data was imported and the file names were set from the Corpus
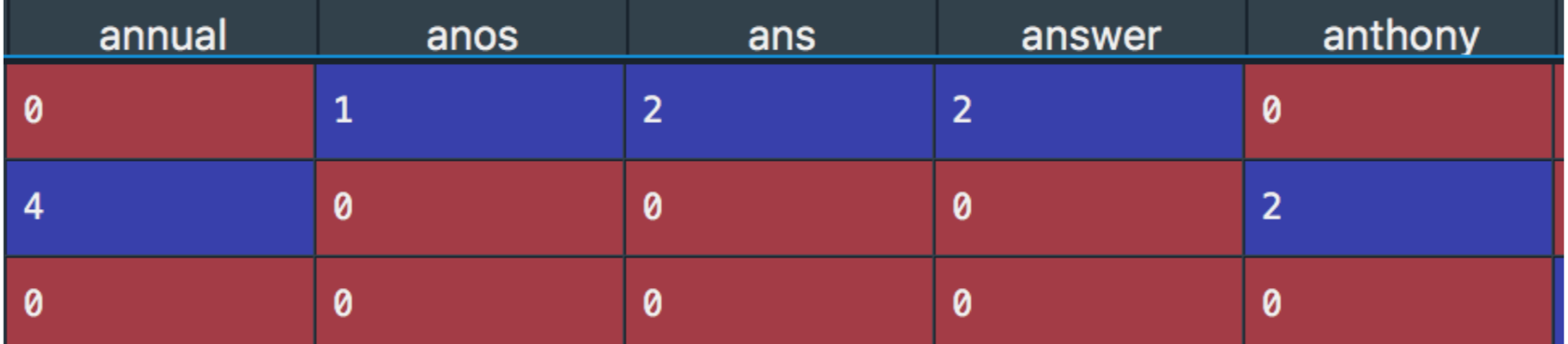
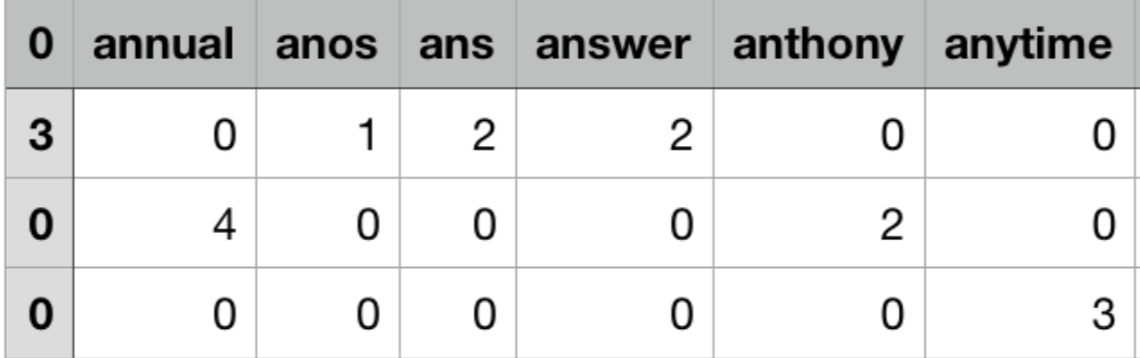
The Data was then run through count vectorizer which created a matrix of word appearances in each text file .
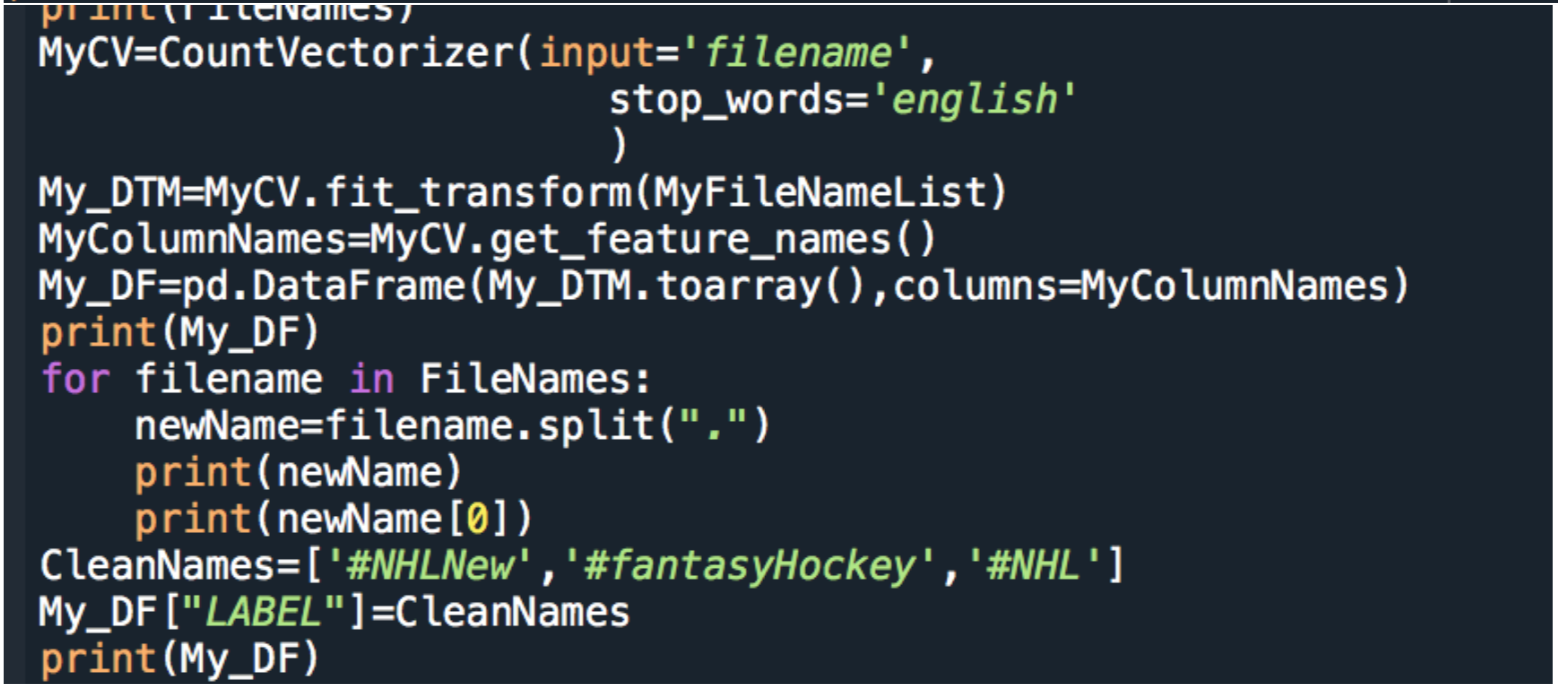
The data frame contained a large number of numeric words which were then removed to decrease the size and remove unneeded words.